
Table of Contents
The UnknownConverterPlugin
- There's a Greenstone 3 tutorial demonstrating how to use the UnknownConverterPlugin. It requires that you find and install a tool that you can run from the command line to convert the unknown document format to text or html.
As an example, the tutorial covers how Greenstone can be made to process djvu files using the UnknownConverterPlugin and a free command line tool that converts djvu to text or html. - In place of installing LibreOffice so that Greenstone can extract text from docx files, the UnknownConverterPlugin can be used in conjunction with Apache-Tika to likewise create a collection where docx files are searchable. The difference is that without LibreOffice, no equivalent html version of the docx file would be produced: you get a text-only html version allowing for full text searching, but not a nice html that reproduces the non-text content and formatting of the docx file. If you want the latter, you would still need the free LibreOffice (or Microsoft Word itself) installed.
Using the UnknownConverterPlugin with Apache Tika to process docx (and other) files
Apache Tika is Apache's open-source software to extract text from countless different (textual) document types, one of which is docx. While one can write code to make calls on Apache-Tika's API, their ready made jar file contained everything that we needed to get Greenstone to index text in docx files.
The steps involve putting a JRE 8 into your Greenstone 3, drop an Apache-Tika jar file into your GS3/gs2build/ext and then configuring an UnknownConverterPlugin instance to make use of it. Building the collection with this will allow Greenstone to process and index docx files to make them searchable without requiring users to install libreoffice.
Steps for users of Greenstone 3 versions after 3.10
Your Greenstone 3, whether running on Windows or Unix systems, is ready to process docx files out of the box.
Run GLI, drag and drop docx files into your collection and after building, full text searching for your docx files will be available.
Steps for 3.10 users
1. Instructions to quickly get a JRE 8 and install it locally into your GS3
Linux users can now start up GLI, drag and drop docx files into a collection. After building, your collection will have full text search for your docx files.
2. Extra step for Windows users:
Use a text editor to edit <your-GS3>/gs2build/collect/modelcol/etc/collectionConfig.xml as follows.
Locate the line that says:
java -jar $GSDLHOME/ext/tika/tika-app-*.jar --html --pretty-print --encoding=UTF-8 %%INPUT_FILE > %%OUTPUT
and change it to say:
java -jar %GSDLHOME%/ext/tika/tika-app-1.24.1.jar --html --pretty-print --encoding=UTF-8 %%INPUT_FILE > %%OUTPUT
Save the modelcol's collectionConfig.xml file before closing.
Now you can run GLI, drag and drop docx files into your collections and after building you'll now have full text search for your docx files.
Steps for 3.09 users
The UnknownConverterPlugin has been officially available since Greenstone 3.09, so that 3.09 users can also start using Tika with the plugin, by
0. following the quick steps here to get a JRE 8 (32 bit only for Windows) and have it locally installed in your Greenstone 3, as the bundled version is JRE 7 and not compatible with tika-app-1.24.1.jar
1. creating a subfolder called "tika" inside their GS3-install-dir/gs2build/ext,
2. downloading the Apache-Tika binary jar file from https://www.apache.org/dyn/closer.cgi/tika/tika-app-1.24.1.jar (or by visiting http://trac.greenstone.org/browser/main/trunk/greenstone2/ext/tika/tika-app-1.24.1.jar and clicking the link labelled "downloading" there), then dropping the downloaded jar file into GS3/gs2build/ext/tika
3. and then configuring an UnknownConverterPlugin instance for any collection that needs docx processing as follows. Note that windows users need to type %GSDLHOME% in place of $GSDLHOME in the following and type the full name of the tika-app jar file: tika-app-1.24.1.jar.
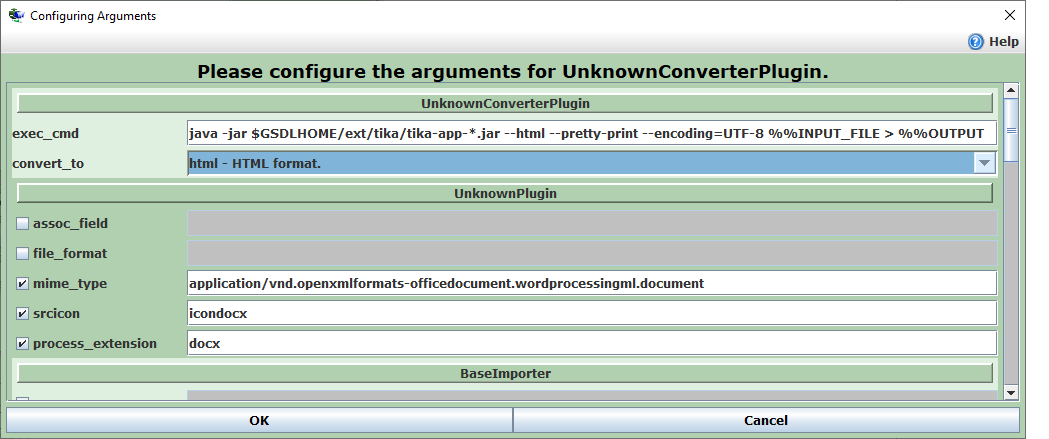
All 3 of the above steps are already setup for you in the GS3 binaries generated every night and available from http://www.greenstone.org/caveat-emptor/
Untried: Greenstone 2 users can try a grabbing a nightly GS2 binary from http://www.greenstone.org/caveat-emptor/ as it should also come with an UnknownConverterPlugin). The nightly GS2 binaries should already have an ext/tika subfolder within the GS2-installation folder, containing the tika jar file. Otherwise you can create this folder yourself and download the tika jar file into that location as in step 2. Next configure your UnknownConverterPlugin as in step 3 above before building your GS2 collection containing docx files.
You're not limited to processing docx files by using UnknownConverterPlugin with Tika. You can process other textual doc types, whether already supported by existing Greenstone plugins or not, by configuring a new instance of UnknownConverterPlugin and setting the mime_type, srcicon, process_extension (and file_format) fields appropriately for that doctype.
For every doctype to be processed by UnknownConverterPlugin, the plugin requires you to have a command line tool installed that can convert that doctype to text or html. Apache-Tika supplies that, being the actual command line tool that can convert from a textual doctype to text or html. Next time you have a collection containing doctypes for which Greenstone does not provide existing plugins, experiment with the combination of the UnknownConverterPlugin with Tika.
Download JRE 8 and install locally into your GS3
GS3 comes bundled with JRE 7, but the bundled tika-app-1.24.1.jar needs JRE 8+.
The following steps for your Operating System will have you quickly set up with a JRE 8 local to your Greenstone 3 installation.
For Windows users:
a. Use a File Explorer to do the following on the file system:
- Rename
<your-GS3>\packages\jreto<your-GS3>\packages\jre.orig - Create folder
<your-GS3>\packages\jre
b. Visit: https://www.java.com/en/download/manual.jsp
c. Click the "Windows Offline" link (which is the Java 8 update 301 for 32 bit win).
It has to be the 32 bit, don't get the 64 bit as then MG/MGPP indexers and GDBM will not work without manually recompiling Greenstone 3.
d. Then run the JRE windows installer and at the start of the installer, ensure you tick "Change destination folder" tickbox at the bottom.
- Set the destination folder to
<your-GS3>\packages\jre - Run through the installer
The above steps will have put a compatible JRE8 into <your-GS3>/packages/jre
For Linux users:
a. Rename <your-GS3>\packages\jre to <your-GS3>\packages\jre.orig
b. Visit: https://www.java.com/en/download/manual.jsp
c. Click the "Linux x64" link, which is the Java 8 update 301 for Linux x64.
d. Put the downloaded tar.gz into the <your-GS3>/packages/ folder.
Decompress.
You may now have ended up with a decompressed folder like jre-… possibly containing yet another subfolder jre…. Ultimately there will be bin and other subfolders in there somewhere.
Move any jre… folder that immediately contains a bin and the other subfolders into <your-GS3>/packages/, so you don't have more than one level of any folder called jre….
Then rename the jre… folder to just jre.
You want to end up with this file structure: <your-GS3>/packages/jre/bin